
Webサイトの運営をしていると必ずと言って良いほどクローラという言葉を聞くことになります。またクローラにインデックスさせるという横文字の単語が多く登場します。これらの言葉の意味は理解できていますか?ゼロから分かりやすく解説するのでしっかり押さえておきましょう!
この記事はこんな人におすすめです!
- クローラやインデックスの意味を知りたい
- クローラが何をしているのかを知りたい
- クローラとインデックスの関係性が分からない
クローラの基礎知識
まず結論からいえば、クローラは検索結果を表示するためにインデックス登録を実施している、ということになります。この記事を読了すれば言葉の意味を理解できるようになります。
クローラとは?

クローラ(crawler) とはWebサイトを巡回するためのプログラムのことです。這うという英語の crawl が由来です。GoogleやBingなどの検索エンジンごとにクローラが存在しており、日夜世界中のWebサイトをかけめぐっています。クローラはプログラムなので特殊なことがなければ決して休むことはありません。「Webサイトをクローラが訪問する」という意味で「Webサイトをクロールする」といった言葉の使われ方をします。そしてクローラはWeb上に存在するページをインデックスするためにWebサイトを巡回しているのですが、次はインデックスという言葉の意味を説明しましょう。
インデックスとは?
インデックス(Index)とは検索結果の辞書に登録することです。検索結果の辞書に登録するという意味で「インデックスに登録する」と使うこともあれば、直接「インデックスする」と言うこともあります。例えばラーメンのWebサイトを事前にクローラが巡回し、その結果を辞書に登録(= インデックス登録)しますするとあなたが「ラーメン おすすめ」と検索したときに、そのラーメンのサイトを検索結果として表示してくれます。言い換えればインデックスをされないとページは検索結果に表示されません。クローラはインデックス登録を実施して、GoogleやBingの検索結果に表示させるために動作しています。
 検索結果に表示されるのはインデックス登録したおかげ
検索結果に表示されるのはインデックス登録したおかげ
クローラの一般的な動き
さてここまでの話をまとめるとクローラは一般的に以下のような流れで動作しています。
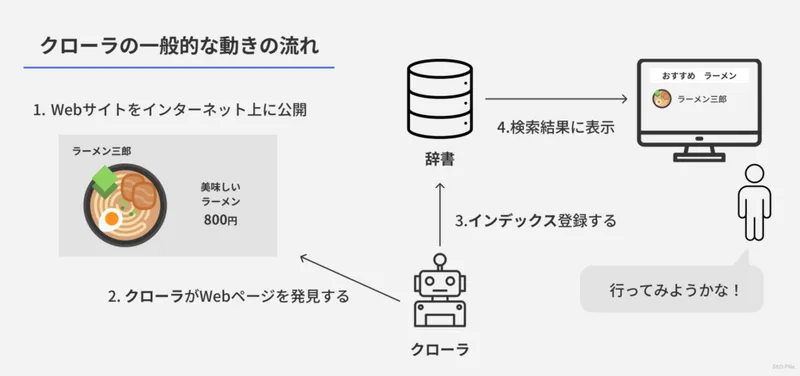
- あなたがWebサイトに新しいページをインターネット上に公開する
- 公開されたインターネット上のページをクローラが発見する
- クローラは発見したページをインデックス登録する
- インデックス登録されたページは検索結果に表示されるようになる
あくまでも一般的な流れになります。例えばWebページを発見したものの、インデックスは登録しない場合などもあります。
クローラの仕組み
クローラの仕組みは?
これでクローラの動きは理解できました。ではもうすこし掘り下げてクローラの仕組みについて解説していきましょう。クローラはWebサイトを巡回するプログラム、いわゆるボット(Bot)という種類のプログラムになります。ボットとは人の手を介さない自動で動くプログラムのことです。クローラはWebサイトに訪問して何をするのかを説明していきます。
次に「Webサイトをクロールする」とは実際に何をする作業なのかを簡単に説明します。そもそもですが、Webサイトのクロールの仕組みは公開されていません。なのでクローラが細かくどのような動きをするか厳密には知ることはできません。しかし「クローラがこんな感じに動くからこの通りに作ってね」というドキュメントは各検索エンジンごとが公開しており、それを参考にするしかありません。このセクションで紹介することは各検索エンジンで共通かつ一般的な知識にとどめて説明をします。
クローラはページを訪問して何をする?
クローラは各Webサイトを訪問してそのページ内容をチェックします。そして訪問したページのHTML、画像、動画など様々な情報を取得しますが、そのなかでも最も分かりやすいメタタグでしょう。メタタグって何ですか?という方は以下の記事を参考にしてください。
メタ(meta)タグとは?SEOにおける重要な6種類のメタタグをわかりやすく説明
メタタグの一例をあげて紹介しましょう。例えば本サイトでは以下のようなメタタグが設定されています。
<title>SEO Plus | WebサイトのSEO改善レシピ</title>このタイトルのメタタグを読み込むと、それを辞書であるインデックスに登録します。そしてインデックスに登録したメタタグの情報は、検索結果を問い合わせたときにサイトのタイトル情報として画面に表示するということです。
メタタグ以外にも画像検索のために画像をインデックスに登録したり、ニュースとしてインデックスに登録したりと、インデックスには非常に多様な情報が保存されます。またWebサイトのクローラのしやすさをクローラビリティと呼ぶことがあります。
ちなみに浮かび上がる疑問として、検索結果は何を基準にランキング(表示順) を作成しているのか、です。この仕組みも公開されていません。自分のWebサイトを検索結果の上位に表示させるために、Webサイトを最適化する手法をSEOといいます。
クローラがサイトを訪れる頻度は?
次にクローラがWebサイトを巡回する頻度はどの程度なのでしょうか?残念ながらその頻度も公開されていません。クローラの巡回頻度はそのサイトの性質によって大きく幅があると言われています。つまり、更新が多いサイトはクローラが頻繁に来訪して、逆に更新が少ないサイトは数ヶ月に一回という場合もあるようです。
ただし管理者がサイトへの負荷を考慮してクロールの頻度を落とすことはできます。また各検索エンジンが用意するコンソールにアクセスすることで手動でクロール、インデックスさせたいURLを登録させることもできます。ここではその方法は個別の検索エンジンの方法に依存するため、方法については各ドキュメントを参考にしてください。
クロール対象のページを管理者が制御する方法
 サイトマップの一例
サイトマップの一例
管理者はサイトマップというサイトの地図をクローラに与えることで制御させることができます。クローラは基本的にはリンクをたどって自動でWebページをクロールし、ページをインデックス登録します。これは私たちがブラウザを使ってWebブラウジングをするときと似ています。あくまでも自動が基本ですが、サイトマップを事前にクローラに認識させておけば、クローラが訪問するページをある程度コントロールできます。
「ある程度」と書いたのは完全にはコントロールできないためです。ここまで読んでいただいた方であれば理解できると思いますが、クローラは誘導はできても完全にコントロールさせることはできません。
ここからはコントロールできる範囲での指定方法を紹介しましょう。
index / noindex による制御
クローラにページをインデックスさせる(させない)ための属性です。インデックスさせたいほうにindex 、させたくないほうにnoindex を付与します。デフォルトは 多くの場合は、index です。ページを検索結果に表示させたいわけですから、index をつけるほうが基本になります。ただし、ページによってはクローラにインデックスをさせないほうが良い場合があります。例えば本サイトではプライバシーポリシーや連絡先は noindex を指定しています。これらは検索結果に表示されても仕方ないですよね。
noindex を指定するべきはシンプルに検索結果に表示させなくてもよいページという認識でよいと思います。具体的には、
- 検索結果に表示させる必要がないページ(連絡先、プライバシーポリシーなど)
- 検索結果に表示させたくないページ(認証が必要なページ、非公開ページなど)
が該当します。
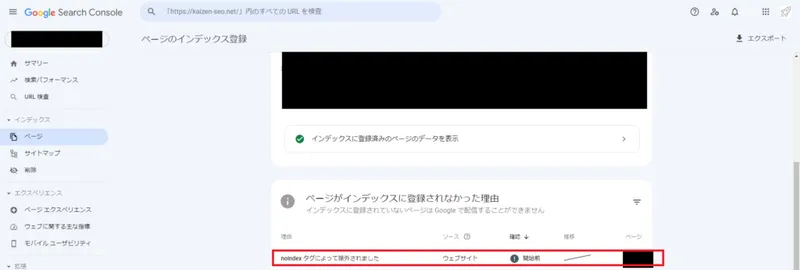
noindex を付与したページは、クロールされないため、Google Search Console で除外されたかを確認することができます。
ページ単位でメタタグを head の間に挿入することで指定することができます。メタタグとは何?という方はこちらの記事を参考にしてください。インデックスをさせたい場合は以下のように記載します。
<meta name="robots" content="index">逆にさせたくない場合はこちら。
<meta name="robots" content="noindex">このタグをクローラが読み取ってそのページをインデックスするかどうかを判断します。 もしくは以下のようにHTTPレスポンスヘッダに付与することでも可能です。こちらはレスポンスヘッダのため、より細やかな制御が可能になっています。
X-Robots-Tag: noindexfollow / nofollow による制御
クローラにページの a タグのリンクを検査させる(させない)ための属性です。検査させたいほうに follow、させたくないほうに nofollow を付与します。クローラは賢いのでページ内リンクをたどっていくことでクロールを進めていきます。このときに「リンク先にはクロールしないように!」と命令するための属性になります。
indexと比較するとどのように付与するべきか迷うところですが、クロールされると不都合なページには nofllow を付与します。
- ユーザが投稿する可能性のあるページ(コメントなど)
- ユーザが投降した内容にリンクがある場合に不都合が生じる
- 有料サイトへのリンク
- 有料サイトにページの評価を渡すことをクローラが禁じているため
- 信頼できないサイトへのリンク
- 信頼できないサイトへサイトのドメインパワーを渡さないため
こちらもメタタグを利用する方法があります。以下のコードを head タグの間に挿入しましょう。
<meta name="robots" content="nofollow">しかし、follow/nofollowは、aタグのリンクに関する制御のため、ページ単位で制御することが難しいことが多いです。そのときは a タグに rel=“nofollow” とつけることでそのタグを検査させないという命令をさせることができます。
<a href="example.com" rel="nofollow"></a>このように指定すれば、クローラは example.com へのリンクをたどらなくなります。
さいごに
クローラの仕組みについて、おおまかに理解できたでしょうか。 実際には頻繁にアルゴリズムの改定が行われており、インターネット上の情報が古い可能性もあります。 できる限り、各検索エンジンのドキュメントを参考に、SEO対策を練るとよいでしょう。