自分のローカル環境で qmd というツールを使い始めてみました。qmd は Shopify CEO の Tobi Lütke が公開しているローカル検索エンジンで、Markdown ドキュメントを BM25 やベクトル検索で横断的に検索できるツールです。
非常に可能性を感じるCLIツールで、ローカルで完結して動作することが特徴的で自身のナレッジベースを横断的に検索することができます。しかしながら…日本語のクエリ展開(query expansion)が英語前提で動いていないことに気づきました。
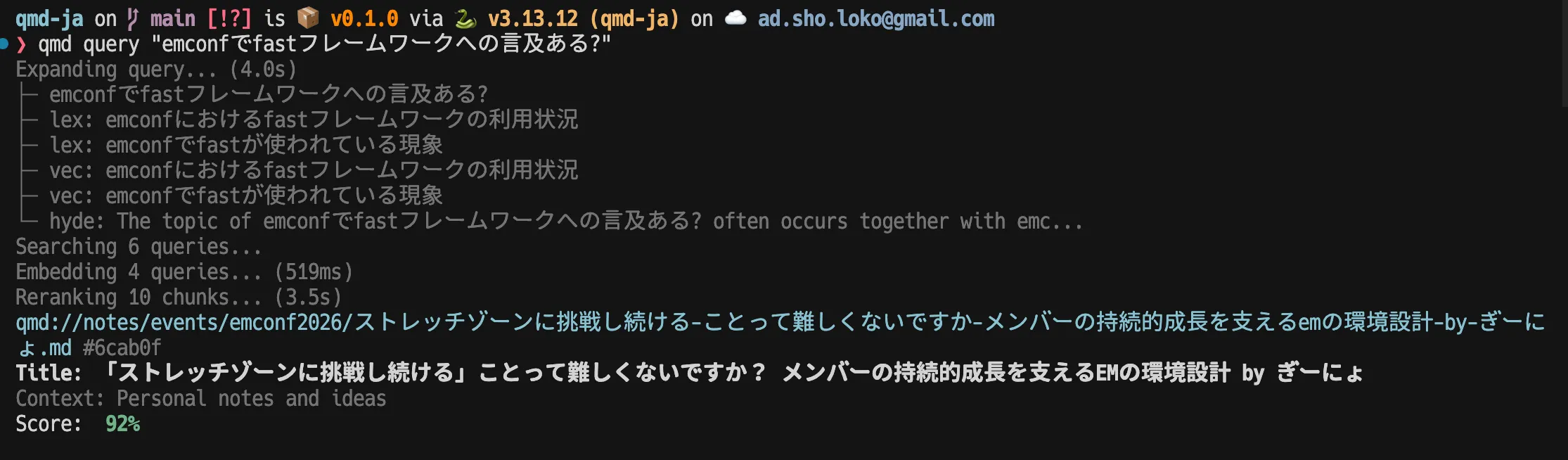
ユーザの質問に対して「クエリ拡張(Query Expansion)」をすることで、 bm25 / knn / hyde 専用のクエリを生成して検索を走らせているようで、Query Expansion モデルを SFT で学習した独自のモデルが利用されています。
しかしながら日本語が含まれる場合は、上手くクエリ拡張(Query Expansion)されない場合があります🥺
❯ ollama run huggingface.co/tobil/qmd-query-expansion-1.7B-gguf
>>> Next.jsのSSRについて教えて // 追記: 何も表示されないパターン
>>> Next.jsのSSRについて教えて // 追記: thinkタグの出力/中国語の出力
</think>
lex: next.jsのssrの基本
lex: next.jsのssrの使い方
vec: 如何使用next.js的ssr
vec: next.jsのssrの基本教程
hyde: 这是关于next.jsのssr的入门教程,涵盖了基本介绍和使用。希望对新手有所帮助!そこで既存の学習済みモデルに、日本語対応の SFT パイプラインを追加で学習してみました。最終的には下記のように独自のモデルが、持ち運び用のMacbook Air M3(24 GB) でも非常に軽快に動作します。
Query Expansion とは
そもそも クエリ拡張(Query Expansion) とは何かを簡単に説明しておくと、ユーザーの検索クエリを同義語や関連語に展開して検索精度を上げる技術です。
たとえば「認証の設定方法」というクエリがあったとして、そのまま BM25 で検索すると「認証」「設定」「方法」という文字列を含むドキュメントしかヒットしません。しかし query expansion で以下のように展開すれば、英語ドキュメントや関連ドキュメントも幅広く拾えるようになります。

各プレフィックスの意味は以下の通りです。
- lex: → BM25 全文検索用(短いキーワード)
- vec: → ベクトル類似検索用(自然言語フレーズ)
- hyde: → HyDE(仮説ドキュメント埋め込み)用の仮想ドキュメント
ただし完全に英語前提で作られているため、日本語でまともに使うにはそれなりの改修が必要です。 qmd の finetune パイプラインでは、この展開を LLM に学習させて、小さなモデルでも高速に実行できるようにしています。 これを日本語向けにも作成していこうというわけです。

全体の構成
すべてのソースコードはMITライセンスで公開しています。
またファインチューニングしたモデルは HuggingFaceにアップロード済みです。
さて最終的なリポジトリ構成は以下に落ち着きました。
qmd-ja/
├── pyproject.toml
├── dataset/
│ ├── schema.py # JSONL スキーマ検証
│ ├── prepare_data.py # chat template 適用 + split
│ └── upload_to_hub.py # HF Hub アップロード
├── data/
│ └── *.jsonl # 学習データ
├── reward.py # 日本語向けスコアリング
├── evals/queries.txt # 日本語テストクエリ
└── jobs/
└── sft.py # HF Jobs 自己完結スクリプトそれではひとつずつ解説をしていきます。
SFT パイプラインの構築
qmd では finetune ディレクトリにてSFT(教師ありファインチューニング)される形でこのクエリ拡張を実装しています。
LoRA を利用した PEFT のため、クエリ拡張のファインチューニングにおけるパイプライン全体は以下のような流れにしました。
data/*.jsonl (学習データ)
↓
dataset/prepare_data.py (Qwen3 chat template 適用 + train/val split)
↓
dataset/upload_to_hub.py (HuggingFace Hub にアップロード)
↓
jobs/sft.py (HF Jobs で Unsloth SFT 実行)本家のリポジトリでは、ローカル実行向けの環境とHugging Face Jobsが分離されていましたが、自分は Colab 以外の手段で学習したことがなく、手元に学習用途で使える端末がないため、Hugging Face Jobs を利用してみることにしました。Jobを動かすためにお金はかかるのですが、学習時間は大きく効率化されますし、なにより GPU を回してみたかったので。実際には $1 程度でおさまりました。
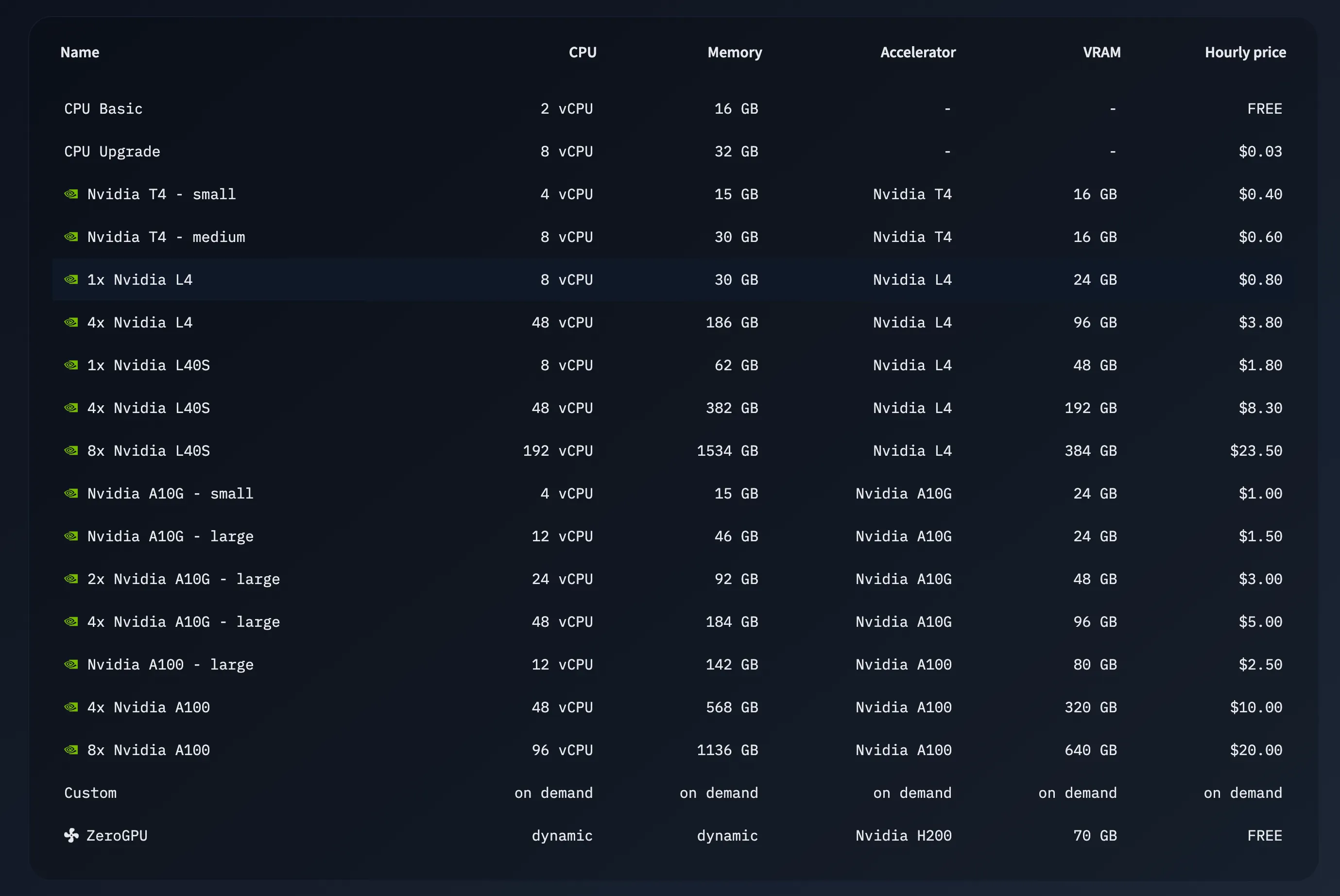
ベースモデルには、tobil/qmd-query-expansion-1.7B の学習済みモデル(Qwen3-1.7B ベース)に LoRA アダプタを追加学習する方法を取りました。Unsloth に対応済みで、1.7B パラメータなら a10-small で学習を回しました。
学習データの生成
教師ありファインチューニングのため、当然ですが教師データが必要になります。今回の場合は要件が明確で元のリポジトリであるデータセットを参考に日本語で妥当なデータセットを生成すればよいだけです。例えば データベース接続のタイムアウト というクエリがあった場合、全文検索としては データベース タイムアウト 、ベクトル検索としては、 DB接続がタイムアウトする理由 、 HyDE では仮想の答えを出力させるため、 データベース接続のタイムアウトは、接続プールの設定やネットワーク遅延が原因で発生しますといった答えが返ってくればよいでしょう。したがって下記のような json を300ケース超用意し、学習用のデータとしました。
{"query": "データベース接続のタイムアウト", "output": [["lex", "データベース 接続 タイムアウト timeout database connection 時間超過"], ["lex", "接続エラー connection error 接続失敗 コネクション 確立 establish"], ["lex", "タイムアウト設定 timeout設定 接続プール pool 待機 wait"], ["vec", "データベースへの接続が時間切れになる問題を解決する方法"], ["vec", "DBコネクションがタイムアウトするときの原因と対処法"], ["hyde", "データベース接続のタイムアウトは、接続プールの設定やネットワーク遅延が原因で発生します。connectTimeout および socketTimeout の値を環境に合わせて調整し、接続プールのmax_idleやmax_lifetimeを適切に設定することで解消できます。また、接続が長時間アイドル状態になる場合はkeepaliveの有効化も有効です。"]]}評価について
ハイパーパラメータは jobs/sft.py の上部にインラインで集約しており、ここはベースモデルやベストプラクティスからチューニングはほとんど行っていません。英語版 LoRA 学習済みモデルのパラメータ更新をしていくLoRAモデルの継続学習になります。データセットを 9:1 で train/eval split して学習を進めていきます。この点は一般的な教師あり学習で、特筆するポイントはありません。
{'loss': '2.729', 'grad_norm': '1.811', 'learning_rate': '0.0001385', 'epoch': '0.197'}
{'loss': '1.727', 'grad_norm': '0.897', 'learning_rate': '0.0001997', 'epoch': '0.3941'}
{'loss': '1.548', 'grad_norm': '0.7889', 'learning_rate': '0.0001979', 'epoch': '0.5911'}
{'loss': '1.446', 'grad_norm': '0.7498', 'learning_rate': '0.0001944', 'epoch': '0.7882'}
{'loss': '1.409', 'grad_norm': '0.7162', 'learning_rate': '0.0001893', 'epoch': '0.9852'}
{'eval_loss': '1.383', 'eval_runtime': '1.708', 'eval_samples_per_second': '26.34', 'eval_steps_per_second': '7.025', 'epoch': '0.9852'}
{'loss': '1.284', 'grad_norm': '0.6751', 'learning_rate': '0.0001827', 'epoch': '1.177'}
{'loss': '1.172', 'grad_norm': '0.8423', 'learning_rate': '0.0001655', 'epoch': '1.571'}
{'loss': '1.207', 'grad_norm': '0.8715', 'learning_rate': '0.0001552', 'epoch': '1.768'}
{'loss': '0.9899', 'grad_norm': '0.93', 'learning_rate': '0.0001319', 'epoch': '2.158'}
{'loss': '0.9329', 'grad_norm': '1.195', 'learning_rate': '0.0001193', 'epoch': '2.355'}
{'loss': '0.9259', 'grad_norm': '1.057', 'learning_rate': '0.0001065', 'epoch': '2.552'}
... さらに、SFT はあくまでも lex: などから始まる形式を模倣するもので、本家では学習済みモデルをルールベースの指標で評価しています。評価の「採点ロジック」はすべて reward.py にまとまっていて、SFT の評価と GRPO の報酬の両方で共通利用(Single Source of Truth)となっています。
本家ではスコアは複数の軸で構成されており、最大 140 点です。
| 指標 | 点数 | 評価内容 |
|---|---|---|
| Format | 0–30 点 | 各行が lex: / vec: / hyde: のいずれかで始まっているか |
| Diversity | 0–30 点 | lex: と vec: の両方が存在するか。フレーズの繰り返しや元クエリの丸写しになっていないか |
| HyDE | 0–20 点 | hyde: 行があり、50〜200 文字程度の自然な説明文になっているか |
| Quality | 0–20 点 | lex: がキーワード寄り・vec: が自然言語文寄りか。重要語の欠落や文法の乱れがないか |
| Entity | -45〜+20 点 | クエリ中の固有名詞(人名・地名・プロジェクト名など)が lex: / vec: 両方に含まれているか。欠落・破壊されると減点 |
| Think bonus | 0–20 点 | /no_think 指示に従い <think> ブロックなしで直接出力しているか(従っていれば加点) |
興味深い点として、Think bonus といって reasoning を行わないようにすることを一つのスコアリングする点は非常に興味深いですよね。
今回のプロジェクトでは本家と同じスコアリングではなく、日本語向けに独自の reward を作成して比較できるようにしました。
日本語向け評価スクリプトの作成と結果
ファインチューニング後、本家の reward.py をベースに日本語向けの評価スクリプト(evals/reward.py)を作成し、ja モデルと base モデルの比較評価を実施しました。
評価指標
本家の reward.py の指標に加え、日本語特有の評価軸として Japanese quality を追加しています。
| 指標 | 重み | 内容 |
|---|---|---|
| Format | 35% | 各行が lex: / vec: / hyde: のいずれかで始まり、中身が空でないか |
| Japanese quality | 25% | 各行に日本語文字が含まれているか + クエリのキーワードが展開に保持されているか |
| Type diversity | 20% | lex: / vec: / hyde: の 3 タイプが揃っているか |
| Line count | 10% | 有効行数が 3〜9 行の範囲に収まっているか |
| Think | 10% | /no_think 指示に従って <think> ブロックなしで直接出力できているか |
Japanese quality は「日本語の文字が含まれているか」と「クエリのキーワード(カタカナ・漢字・ASCII 技術語)が展開結果に保持されているか」の 2 軸を均等に評価するシンプルな指標です。MeCab による本格的な分かち書きは使わず、正規表現で抽出しています。課題として日本語専用の分かち書きなどをより正確に ground truth として確認するようにしても良いと思います。
比較結果(38 件)
| 指標 | ja モデル | base モデル | 差分 |
|---|---|---|---|
| Format (35%) | 100.0% | 95.4% | +4.6% |
| Japanese quality (25%) | 100.0% | — | — |
| Type diversity (20%) | 100.0% | 96.5% | +3.5% |
| Line count (10%) | 100.0% | 100.0% | ±0% |
| Think (10%) | 100.0% | 100.0% | ±0% |
そして…最終的にはそれらしい答えが返ってくるようになりました👏

さいごに
再掲にはなるものの、モデルはHuggingFaceにアップロードしているので、ぜひご活用ください!
Unslothを活用したLoRAのファインチューニングは手軽におこなえて素晴らしいですね。 qmd そのものに強い可能性を感じており、非力なローカル環境で動かせる程度のモデルなので利活用していきたいです。